PDF) Incorporating representation learning and multihead attention
Por um escritor misterioso
Descrição

An interpretable ensemble method for deep representation learning - Jiang - Engineering Reports - Wiley Online Library
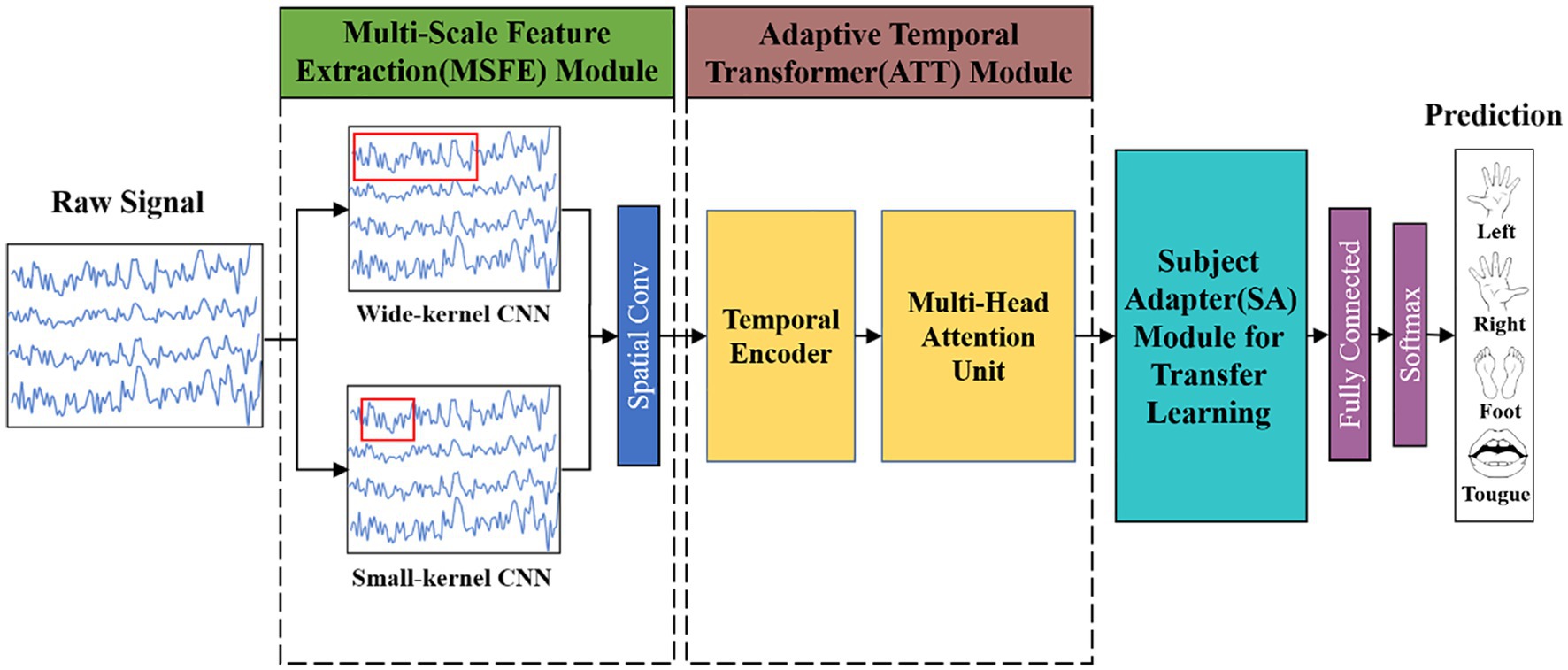
Frontiers MSATNet: multi-scale adaptive transformer network for motor imagery classification

PDF] Interpretable Multi-Head Self-Attention Architecture for Sarcasm Detection in Social Media
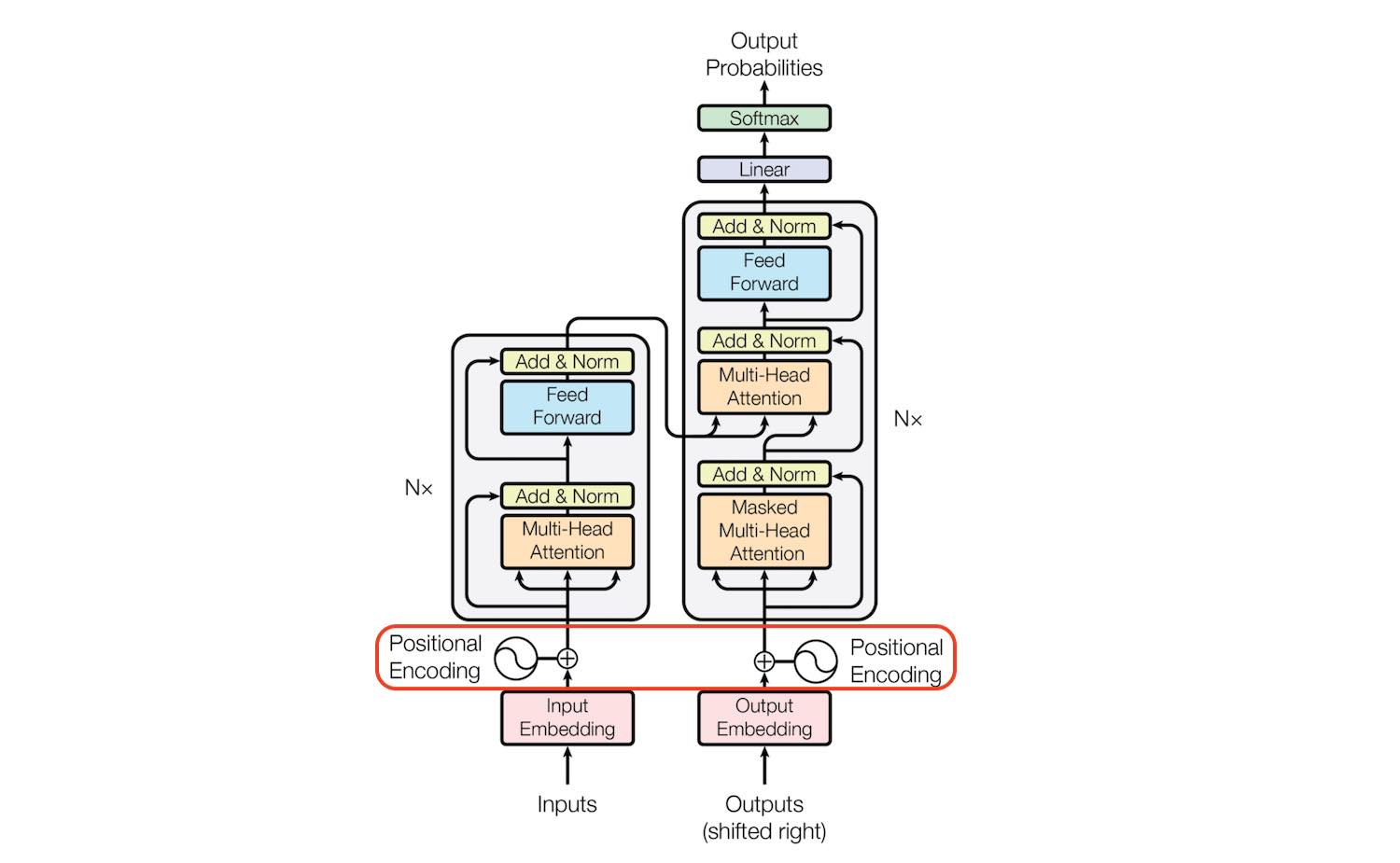
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog

Integrated Multi-Head Self-Attention Transformer model for electricity demand prediction incorporating local climate variables - ScienceDirect
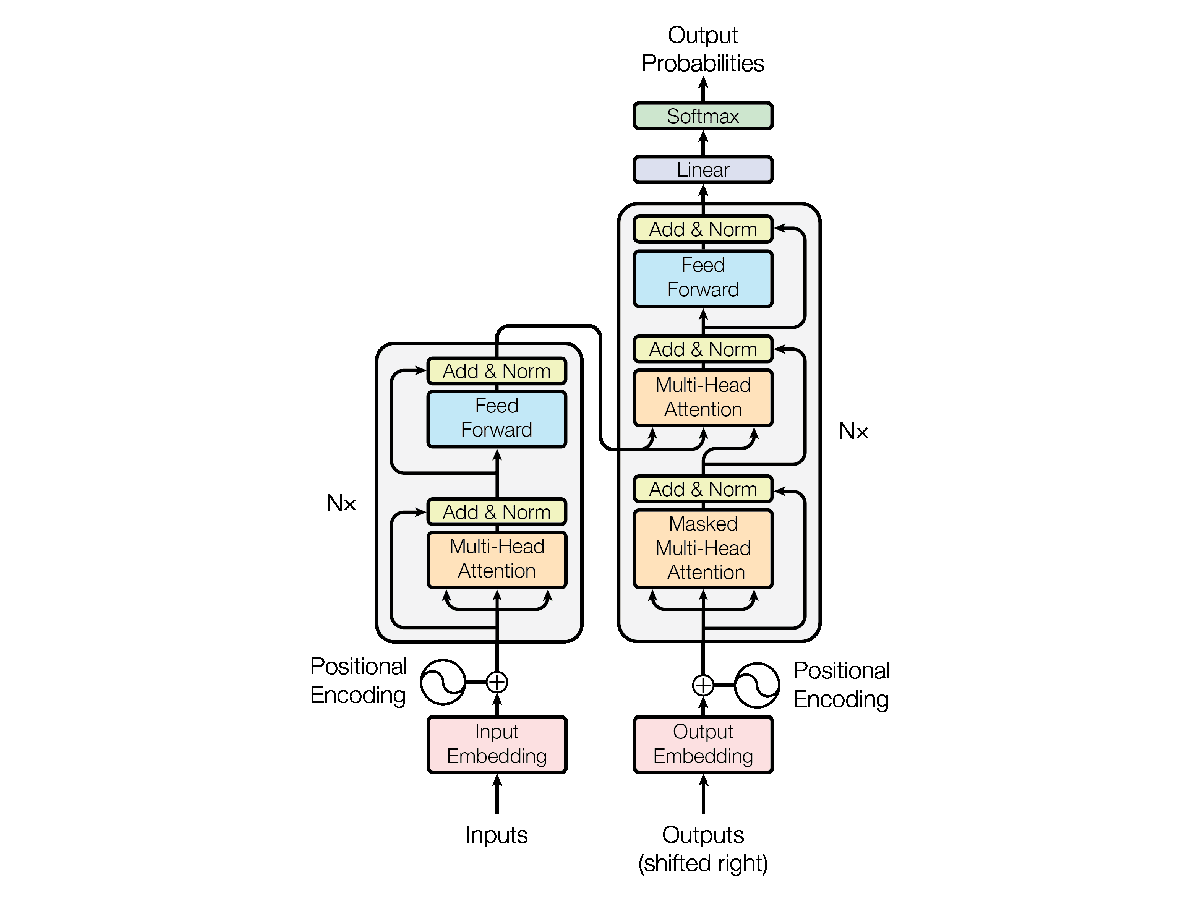
Understanding the Transformer Model: A Breakdown of “Attention is All You Need”, by Srikari Rallabandi, MLearning.ai

Tutorial 6: Transformers and Multi-Head Attention — UvA DL Notebooks v1.2 documentation
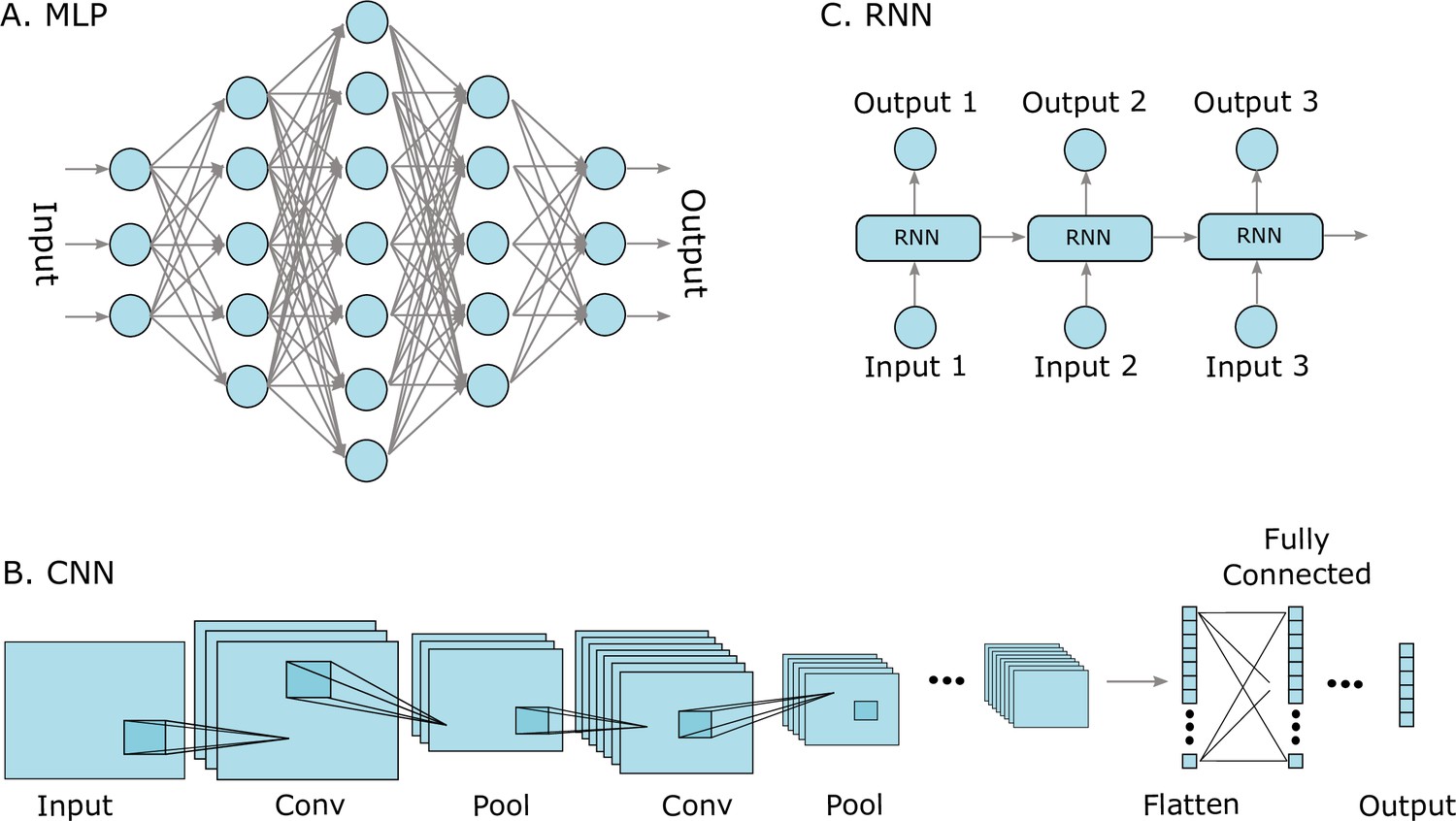
Transformer-based deep learning for predicting protein properties in the life sciences
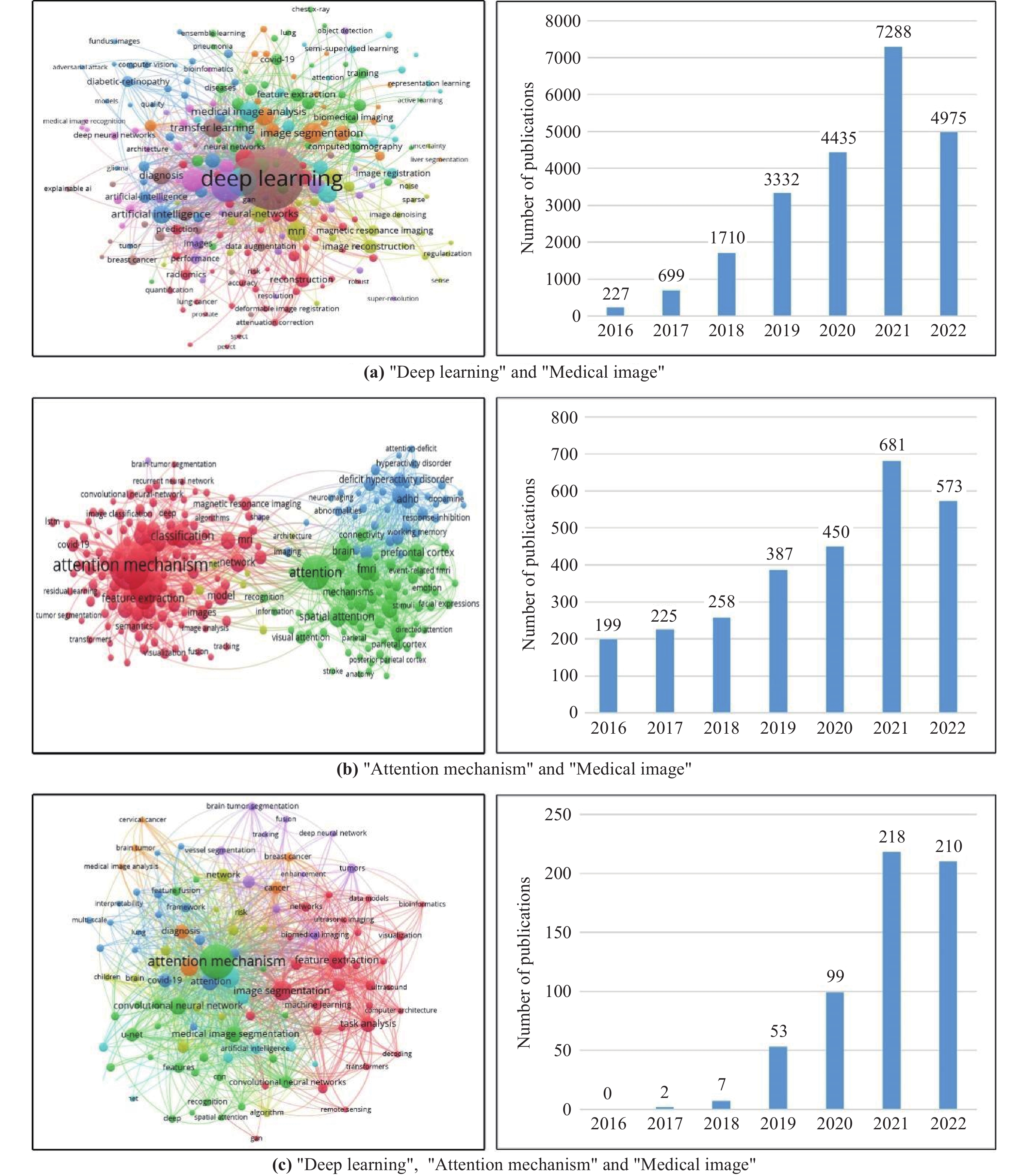
Deep Learning Attention Mechanism in Medical Image Analysis: Basics and Beyonds-Scilight
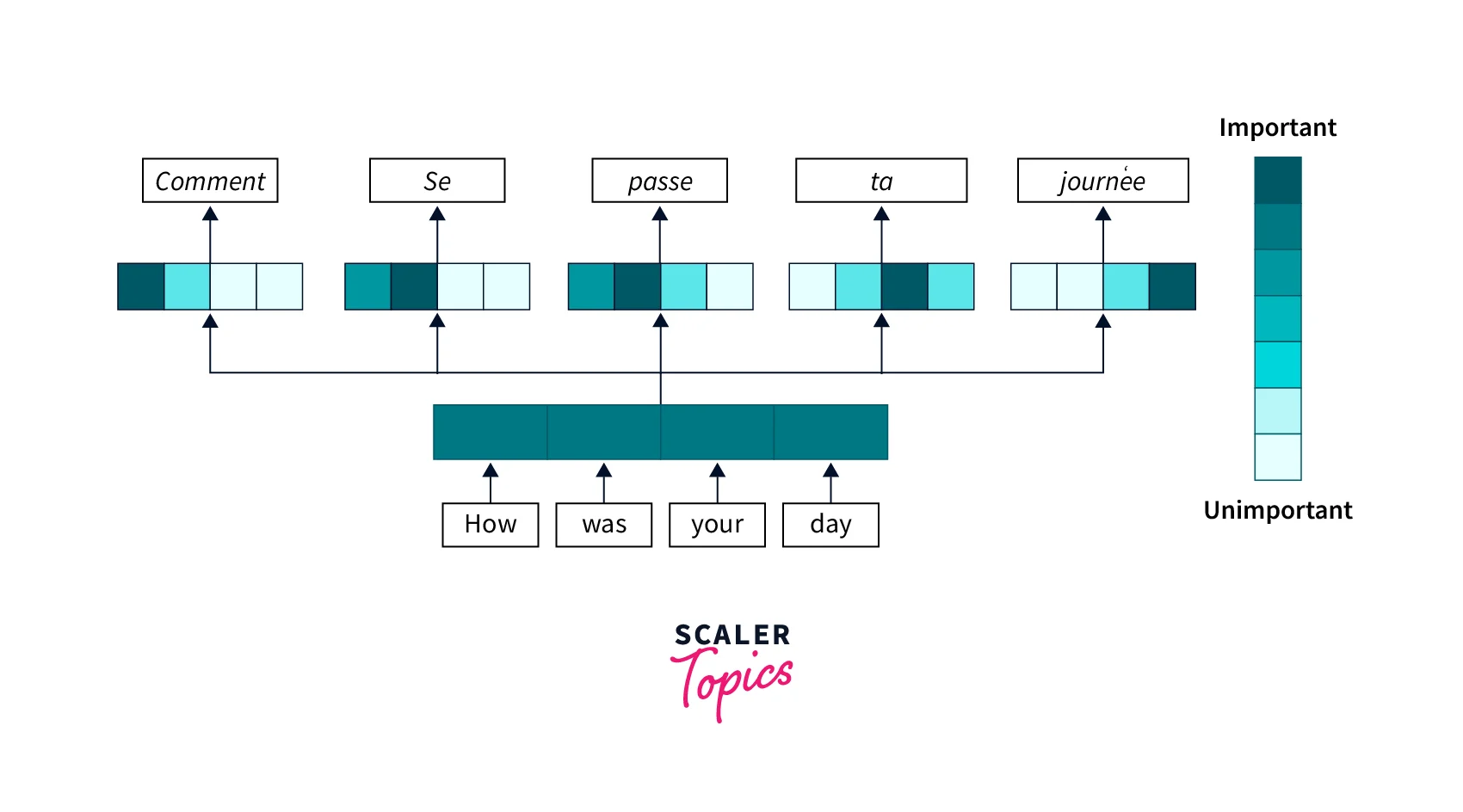
Attention Mechanism in Deep Learning- Scaler Topics

Transformer (machine learning model) - Wikipedia

PDF] Protein Transformer CPI: A Submodel Enhancing Protein Representation Learning in Compound Protein Interaction Prediction
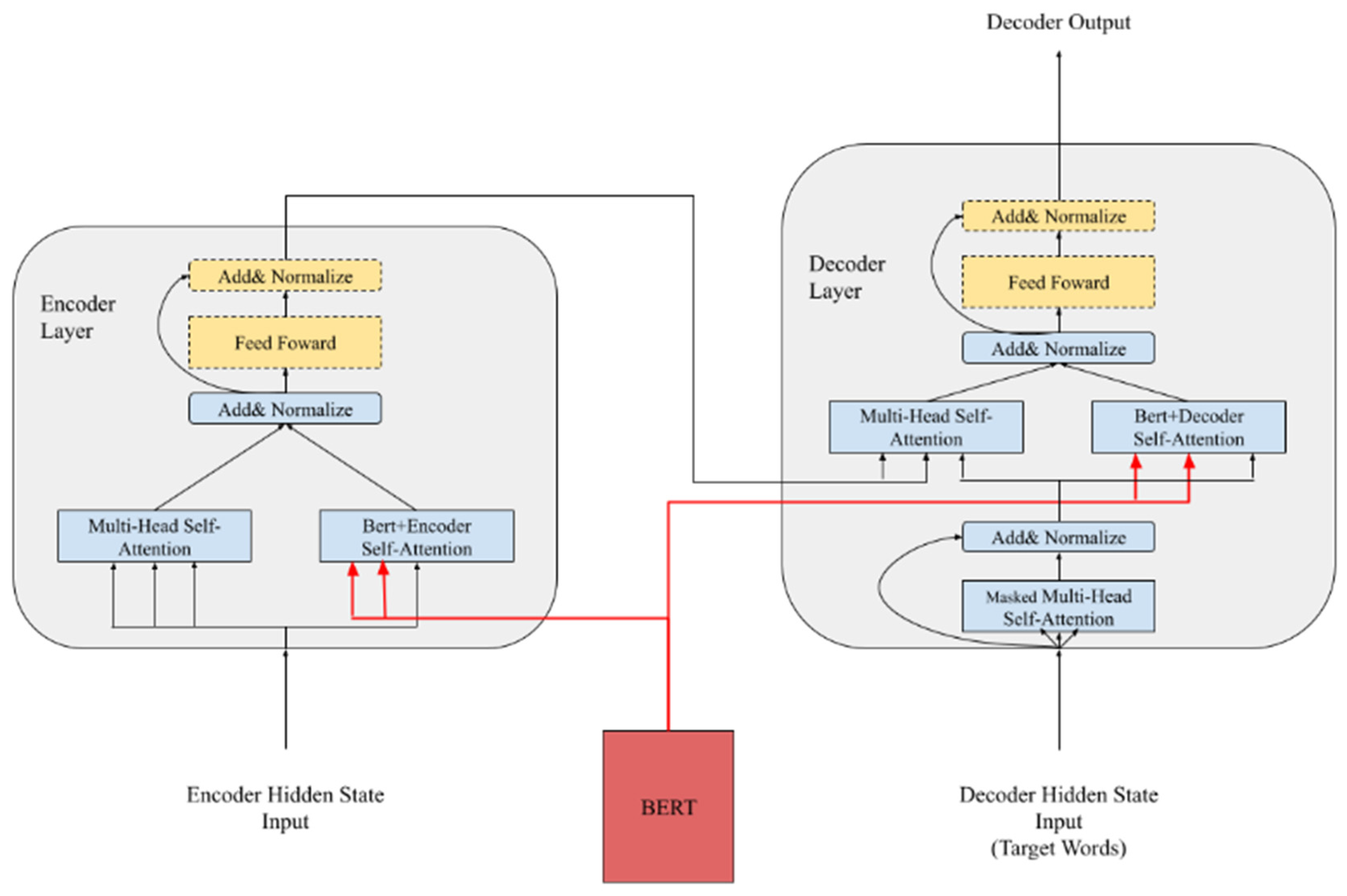
Applied Sciences, Free Full-Text
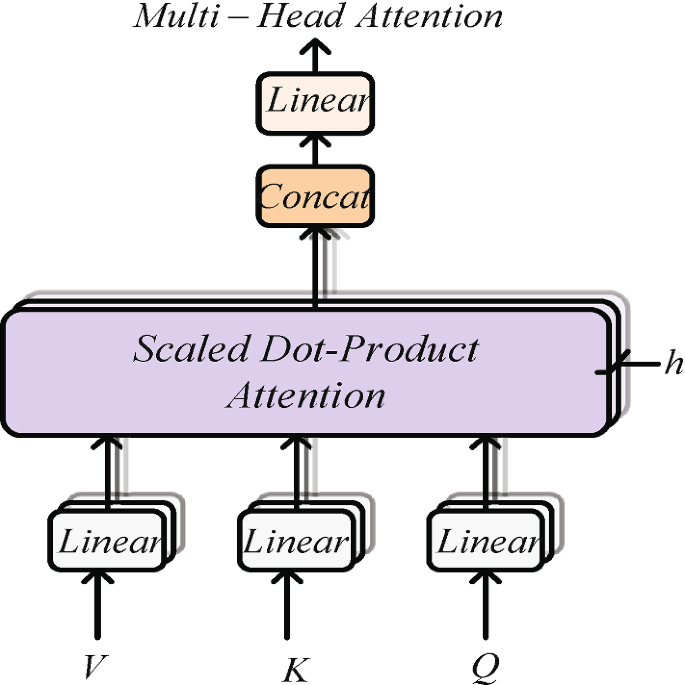
Multi-layer Representation Learning and Its Application to Electronic Health Records
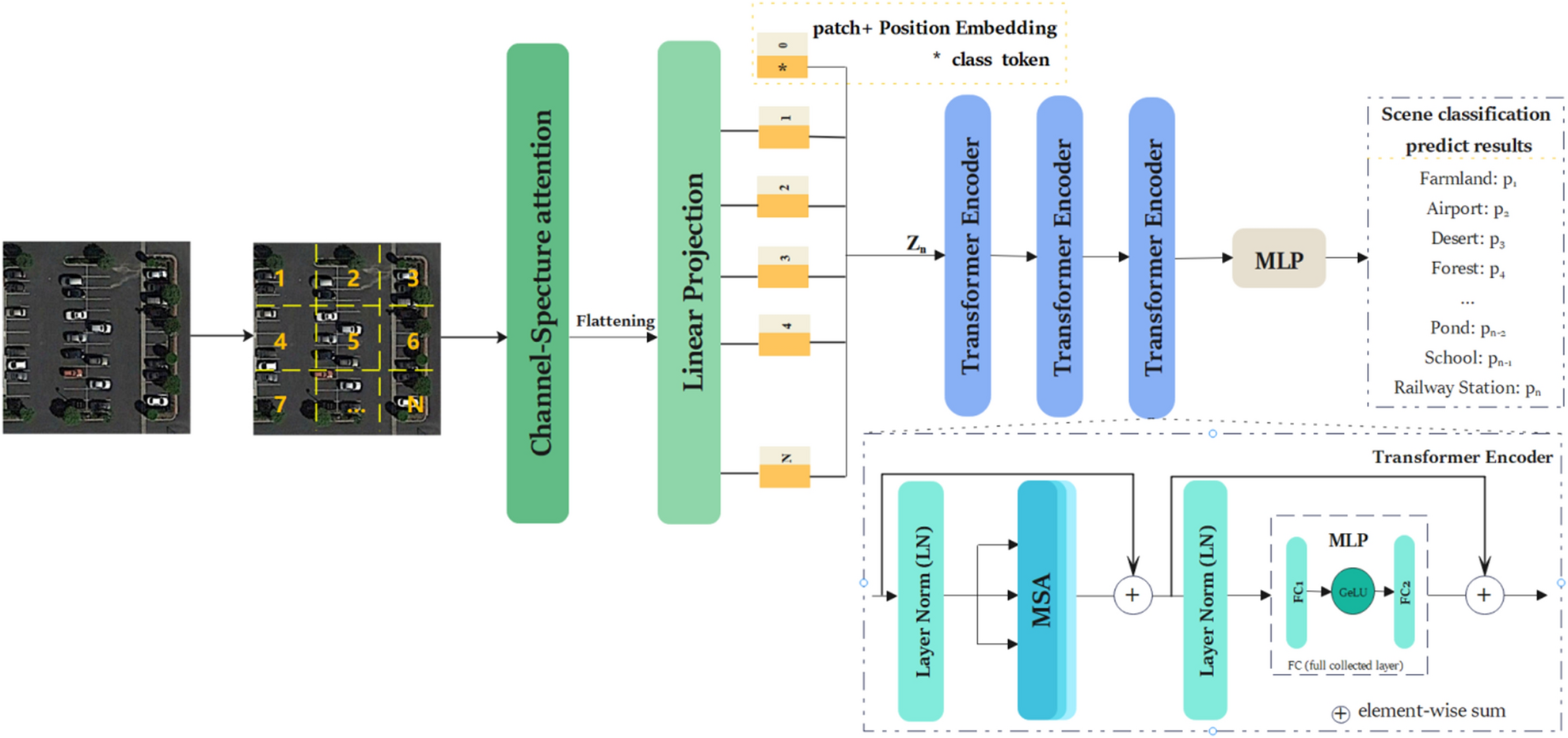
Transformer based on channel-spatial attention for accurate classification of scenes in remote sensing image
de
por adulto (o preço varia de acordo com o tamanho do grupo)







